
Framework e strumenti di AI Generativa che tutti dovremmo conoscere
Nel panorama tecnologico in rapida evoluzione, l’intelligenza artificiale generativa rappresenta una forza rivoluzionaria, trasformando il modo in cui gli sviluppatori e gli ingegneri AI/ML affrontano problemi complessi e innovano. Questo articolo approfondisce il mondo dell’intelligenza artificiale generativa, scoprendo framework e strumenti essenziali per ogni sviluppatore.
LangChain
Sviluppata da Harrison Chase e lanciata nell’ottobre 2022, LangChain funge da piattaforma open source progettata per costruire solide applicazioni basate su LLM, come chatbot come ChatGPT e varie applicazioni su misura.
LangChain cerca di dotare gli ingegneri dei dati di un kit di strumenti onnicomprensivo per l’utilizzo degli LLM in diversi casi d’uso, inclusi chatbot, risposta automatizzata alle domande, riepilogo del testo e altro ancora.
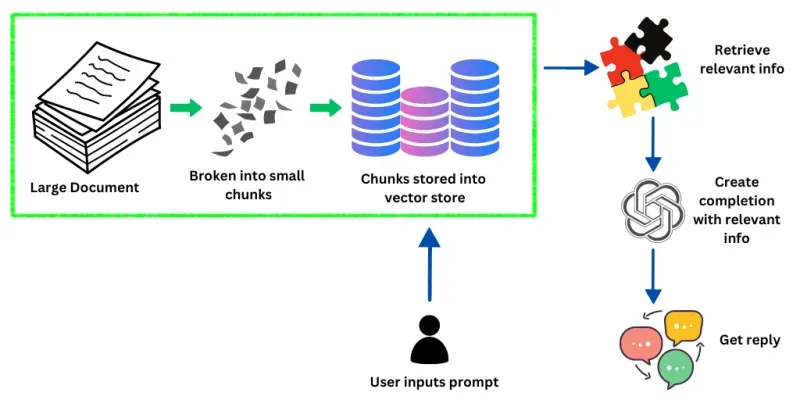
L’immagine sopra mostra come LangChain gestisce ed elabora le informazioni per rispondere alle richieste dell’utente. Inizialmente, il sistema inizia con un documento di grandi dimensioni contenente una vasta gamma di dati. Questo documento viene quindi suddiviso in parti più piccole e più gestibili.
Questi blocchi vengono successivamente incorporati in vettori, un processo che trasforma i dati in un formato che può essere recuperato in modo rapido ed efficiente dal sistema. Questi vettori sono archiviati in un archivio di vettori, essenzialmente un database ottimizzato per la gestione di dati vettorizzati.
Quando un utente inserisce un prompt nel sistema, LangChain interroga questo archivio di vettori per trovare informazioni che corrispondano strettamente o siano rilevanti per la richiesta dell’utente. Il sistema utilizza LLM di grandi dimensioni per comprendere il contesto e l’intento del prompt dell’utente, che guida il recupero delle informazioni pertinenti dall’archivio dei vettori.
Una volta identificate le informazioni rilevanti, LLM le utilizza per generare o completare una risposta che risponda accuratamente alla query. Questo passaggio finale culmina con la ricezione da parte dell’utente di una risposta su misura, che è il risultato delle capacità di elaborazione dei dati e di generazione del linguaggio del sistema.
SingleStore Notebook
SingleStore Notebook, basato su Jupyter Notebook, è uno strumento innovativo che migliora significativamente il processo di esplorazione e analisi dei dati, in particolare per coloro che lavorano con il database SQL distribuito di SingleStore. La sua integrazione con Jupyter Notebook lo rende una piattaforma familiare e potente per data scientist e professionisti. Ecco un riepilogo delle sue principali caratteristiche e vantaggi:
- Supporto SQL nativo di SingleStore : questa funzionalità semplifica il processo di interrogazione del database SQL distribuito di SingleStore direttamente dal notebook. Elimina la necessità di stringhe di connessione complesse, offrendo un metodo più sicuro e diretto per l’esplorazione e l’analisi dei dati.
- Interoperabilità SQL/python : consente un’integrazione perfetta tra query SQL e codice python. Gli utenti possono eseguire query SQL nel notebook e utilizzare i risultati direttamente nei frame di dati python e viceversa. Questa interoperabilità è essenziale per un’efficiente manipolazione e analisi dei dati.
- Flussi di lavoro collaborativi : il notebook supporta la condivisione e la modifica collaborativa, consentendo ai membri del team di lavorare insieme su progetti di analisi dei dati. Questa funzionalità migliora la capacità del team di coordinare e combinare le proprie competenze in modo efficace.
- Visualizzazione interattiva dei dati : con il supporto per le librerie di visualizzazione dei dati più diffuse come Matplotlib e Plotly, SingleStore Notebook consente agli utenti di creare diagrammi e grafici interattivi e informativi direttamente all’interno dell’ambiente del notebook. Questa funzionalità è fondamentale per i data scientist che necessitano di comunicare visivamente i propri risultati.
- Facilità d’uso e risorse di apprendimento : la piattaforma è facile da usare, con modelli e documentazione per aiutare i nuovi utenti a iniziare rapidamente. Queste risorse sono preziose per apprendere le nozioni di base del notebook e per eseguire attività complesse di analisi dei dati.
- Miglioramenti e integrazione futuri : il team di SingleStore è impegnato a migliorare continuamente il notebook, con l’intenzione di introdurre funzionalità come l’importazione/esportazione, il completamento automatico del codice e una raccolta di notebook per vari scenari. C’è anche anticipazione per le funzionalità dei bot che potrebbero facilitare la codifica SQL o python in SingleStoreDB.
- Semplificazione dell’integrazione del codice python : un obiettivo futuro è rendere più semplice la prototipazione del codice python nei notebook e integrare questo codice come procedure memorizzate nel database, migliorando l’efficienza e la funzionalità complessive del sistema.
SingleStore Notebook è un potente strumento per i professionisti dei dati, che combina la versatilità di Jupyter Notebook con miglioramenti specifici per l’utilizzo con il database SQL di SingleStore. La sua attenzione alla facilità d’uso, alla collaborazione e alla visualizzazione interattiva dei dati, insieme alla promessa di miglioramenti futuri, lo rendono una risorsa preziosa nelle comunità di data science e machine learning.
LlamaIndex
LlamaIndex è un framework di orchestrazione avanzato progettato per amplificare le capacità di LLM come GPT-4. Sebbene gli LLM siano intrinsecamente potenti, essendo stati addestrati su vasti set di dati pubblici, spesso non dispongono dei mezzi per interagire con dati privati o specifici di un dominio. LlamaIndex colma questa lacuna, offrendo un modo strutturato per importare, organizzare e sfruttare varie origini dati, tra cui API, database e PDF.
Indicizzando questi dati in formati ottimizzati per LLM, LlamaIndex facilita l’esecuzione di query in linguaggio naturale, consentendo agli utenti di conversare senza problemi con i propri dati privati senza la necessità di riqualificare i modelli. Questo framework è versatile e si rivolge sia ai principianti con un’API di alto livello per una configurazione rapida, sia agli esperti che cercano una personalizzazione approfondita tramite API di livello inferiore. In sostanza, LlamaIndex sblocca tutto il potenziale dei LLM, rendendoli più accessibili e applicabili alle esigenze di dati individualizzate.
Come funziona LlamaIndex? LlamaIndex funge da ponte, collegando le potenti funzionalità dei LLM con diverse fonti di dati, sbloccando così un nuovo regno di applicazioni in grado di sfruttare la sinergia tra dati personalizzati e modelli linguistici avanzati. Offrendo strumenti per l’inserimento e l’indicizzazione dei dati e un’interfaccia di query in linguaggio naturale, LlamaIndex consente agli sviluppatori e alle aziende di creare applicazioni robuste e potenziate dai dati che migliorano significativamente il processo decisionale e il coinvolgimento degli utenti.
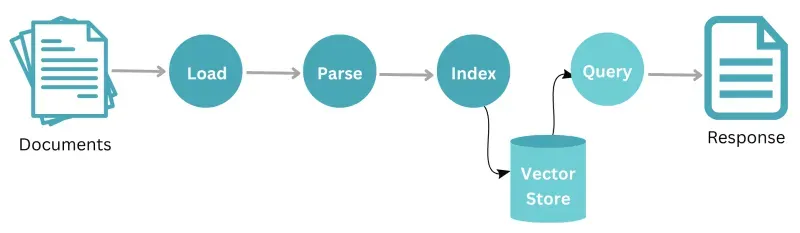
LlamaIndex opera attraverso un flusso di lavoro sistematico che inizia con una serie di documenti. Inizialmente, questi documenti vengono sottoposti a un processo di caricamento in cui vengono importati nel sistema. Dopo il caricamento, i dati vengono analizzati per analizzare e strutturare il contenuto in modo comprensibile. Una volta analizzate, le informazioni vengono quindi indicizzate per un recupero e un’archiviazione ottimali.
Questi dati indicizzati vengono archiviati in modo sicuro in un repository centrale denominato “store”. Quando un utente o un sistema desidera recuperare informazioni specifiche da questo archivio dati, può avviare una query. In risposta alla query, i dati rilevanti vengono estratti e forniti come risposta, che potrebbe essere un insieme di documenti rilevanti o informazioni specifiche da essi ricavate. L’intero processo mostra come LlamaIndex gestisce e recupera i dati in modo efficiente, garantendo risposte rapide e precise alle domande degli utenti.
Lama 2
Llama 2 è un modello linguistico all’avanguardia sviluppato da Meta. È il successore dell’originale LLaMA e offre miglioramenti in termini di scala, efficienza e prestazioni. I modelli Llama 2 spaziano dai parametri 7B a 70B, soddisfacendo diverse capacità e applicazioni di calcolo. Progettato su misura per l’integrazione di chatbot, Llama 2 eccelle nei casi d’uso del dialogo, offrendo risposte sfumate e coerenti che ampliano i confini di ciò che l’intelligenza artificiale conversazionale può ottenere.
Llama 2 è pre-addestrato utilizzando dati online disponibili al pubblico. Ciò comporta l’esposizione del modello a un ampio corpus di dati di testo come libri, articoli e altre fonti di contenuto scritto. L’obiettivo di questa formazione preliminare è aiutare il modello ad apprendere modelli linguistici generali e ad acquisire un’ampia comprensione della struttura del linguaggio. Implica anche la messa a punto supervisionata e l’apprendimento di rinforzo dal feedback umano (RLHF).
Una componente dell’RLHF è il campionamento del rifiuto, che prevede la selezione di una risposta dal modello e l’accettazione o il rifiuto in base al feedback umano. Un altro componente di RLHF è l’ottimizzazione prossimale della politica (PPO) che prevede l’aggiornamento della politica del modello direttamente sulla base del feedback umano. Infine, il perfezionamento iterativo garantisce che il modello raggiunga il livello di prestazioni desiderato con iterazioni e correzioni supervisionate.
Hugging Face
Hugging Face è una piattaforma poliedrica che gioca un ruolo cruciale nel panorama dell’intelligenza artificiale, in particolare nel campo dell’elaborazione del linguaggio naturale (NLP) e dell’intelligenza artificiale generativa. Comprende vari elementi che lavorano insieme per consentire agli utenti di esplorare, creare e condividere applicazioni AI.
Ecco una ripartizione dei suoi aspetti principali:
-
Hub Model: Hugging Face ospita un vasto archivio di modelli preaddestrati per diverse attività di PNL, tra cui classificazione del testo, risposta alle domande, traduzione e generazione di testo. Questi modelli vengono addestrati su set di dati di grandi dimensioni e possono essere ottimizzati per requisiti specifici, rendendoli facilmente utilizzabili per vari scopi. Ciò elimina la necessità per gli utenti di addestrare i modelli da zero, risparmiando tempo e risorse.
-
Dataset: Oltre alla libreria di modelli, Hugging Face fornisce l’accesso a una vasta raccolta di set di dati per attività di PNL. Questi set di dati coprono vari domini e lingue, offrendo risorse preziose per la formazione e la messa a punto dei modelli. Gli utenti possono anche contribuire con i propri set di dati, arricchendo le risorse di dati della piattaforma e promuovendo la collaborazione della comunità.
-
Strumenti di formazione e perfezionamento del modello: Hugging Face offre strumenti e funzionalità per la formazione e il perfezionamento dei modelli esistenti su set di dati e attività specifici. Ciò consente agli utenti di personalizzare i modelli in base alle proprie esigenze specifiche, migliorandone le prestazioni e la precisione nelle applicazioni mirate. La piattaforma offre opzioni flessibili per la formazione, inclusa la formazione locale su macchine personali o soluzioni basate su cloud per modelli più grandi.
-
Creazione di applicazioni:
Hugging Face facilita lo sviluppo di applicazioni IA integrandosi perfettamente con le librerie di programmazione più diffuse come TensorFlow e PyTorch. Ciò consente agli sviluppatori di creare chatbot, strumenti di generazione di contenuti e altre applicazioni basate sull’intelligenza artificiale utilizzando modelli preaddestrati. Sono disponibili numerosi modelli di applicazioni ed esercitazioni per guidare gli utenti e accelerare il processo di sviluppo.
- Comunità e collaborazione:
Hugging Face vanta una vivace comunità di sviluppatori, ricercatori e appassionati di intelligenza artificiale. La piattaforma favorisce la collaborazione attraverso funzionalità come la condivisione di modelli, repository di codici e forum di discussione. Questo ambiente collaborativo facilita la condivisione delle conoscenze, accelera l’innovazione e guida il progresso della PNL e delle tecnologie di intelligenza artificiale generativa. Hugging Face va oltre il semplice deposito di modelli. Funziona come una piattaforma completa che comprende modelli, set di dati, strumenti e una fiorente comunità, consentendo agli utenti di esplorare, creare e condividere facilmente applicazioni AI. Ciò lo rende una risorsa preziosa per individui e organizzazioni che desiderano sfruttare la potenza dell’intelligenza artificiale nei loro sforzi.
Haystack:
Haystack può essere classificato come un framework end-to-end per la creazione di applicazioni basate su varie tecnologie NLP, inclusa ma non limitata all’intelligenza artificiale generativa. Sebbene non si concentri direttamente sulla creazione di modelli generativi da zero, fornisce una solida piattaforma per:
- Generazione aumentata di recupero (RAG):
Haystack eccelle nel combinare approcci generativi e basati sul recupero per la ricerca e la creazione di contenuti. Consente di integrare varie tecniche di recupero, inclusa la ricerca vettoriale e la tradizionale ricerca per parole chiave, per recuperare documenti rilevanti per un’ulteriore elaborazione. Questi documenti servono quindi come input per modelli generativi, risultando in risultati più mirati e contestualmente rilevanti.
- Diverse componenti della PNL:
Haystack offre un set completo di strumenti e componenti per varie attività di PNL, tra cui la preelaborazione dei documenti, il riepilogo del testo, la risposta alle domande e il riconoscimento delle entità denominate. Ciò consente di costruire pipeline complesse che combinano più tecniche di PNL per raggiungere obiettivi specifici.
- Flessibilità e Open Source:
Haystack è un framework open source costruito su popolari librerie NLP come Transformers ed Elasticsearch. Ciò consente la personalizzazione e l’integrazione con strumenti e flussi di lavoro esistenti, rendendolo adattabile a diverse esigenze.
- Scalabilità e prestazioni:
Haystack è progettato per gestire in modo efficiente set di dati e carichi di lavoro di grandi dimensioni. Si integra con potenti database vettoriali come Pinecone e Milvus, consentendo ricerche e recuperi rapidi e accurati anche con milioni di documenti.
- Integrazione dell’IA generativa:
Haystack si integra perfettamente con i modelli generativi più diffusi come GPT-3 e BART. Ciò consente agli utenti di sfruttare la potenza di questi modelli per attività come la generazione di testo, il riepilogo e la traduzione all’interno delle loro applicazioni basate su Haystack.
Sebbene l’attenzione di Haystack non sia esclusivamente sull’intelligenza artificiale generativa, essa fornisce una solida base per la creazione di applicazioni che sfruttano questa tecnologia. I suoi punti di forza combinati nel recupero, i diversi componenti della PNL, la flessibilità e la scalabilità ne fanno un valido framework per sviluppatori e ricercatori per esplorare il potenziale dell’intelligenza artificiale generativa in varie applicazioni.
In conclusione, il panorama dell’intelligenza artificiale generativa è in rapida evoluzione, con framework e strumenti come HuggingFace, LangChain, LlamaIndex, Llama2, Haystack e SingleStore Notebooks in prima linea. Queste tecnologie offrono agli sviluppatori una vasta gamma di opzioni per integrare l’intelligenza artificiale nei loro progetti, sia che lavorino sull’elaborazione del linguaggio naturale, sull’analisi dei dati o su complesse applicazioni di intelligenza artificiale.